[운영체제 공룡책] 11-15. Storage management
반응형
11. Mass Storage Structure
- Mass-Storage
- 비휘발성 (non-voliatie, Secondary Storage
- 보통 하드디스크나 NVM이라 칭함, 제 2 저장 장치 혹은 보조 저장장치라고 함
- 때로는 마그네틱 테입이나, 광학 디스크, 클라우드 저장소를 사용하는 경우가 있음
- RAID 시스템을 이용함
- 전통적인 HDD 스케쥴링
- 다스크에 대한 입출력은 왜 굉장히 느릴까? (교수님보다 설명 잘함)
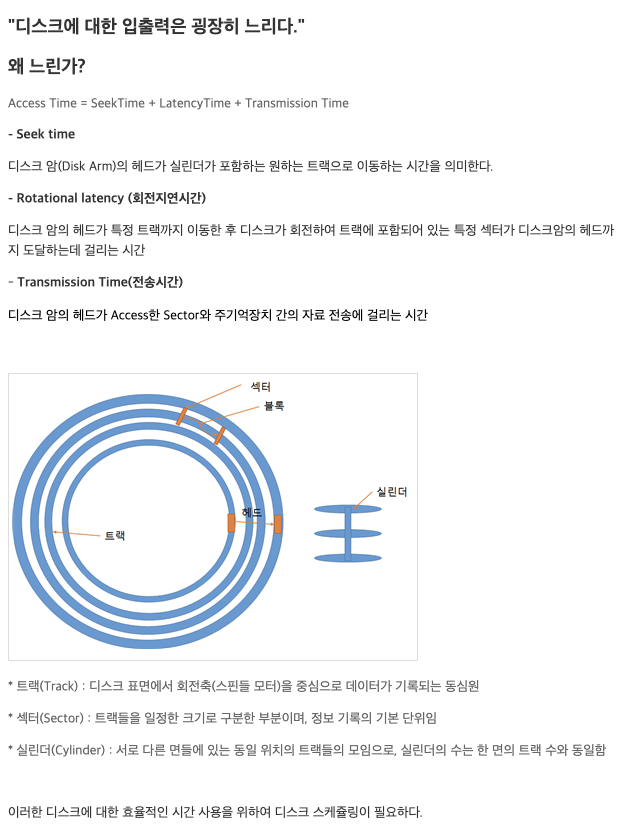
seek time(or 액세스 시간을 최소화)- deivce arm이 head를 움직이는 데, 특정 실린더의 특정 섹터를 찾아가는 데 걸리는 시간을 의미함 (이게 제일 오래걸림)
- rotational latency : 하드가 빙글빙글 돌면서 내가 원하는 섹터에 도달하기까지 소요되는 시간 중 제일 오래 걸리는 시간?
- data transfer의
bandwidth를 최대화- 한번에 데이터를 읽어올 수 있는 양
- FIFO Scheduling
- 먼저 온 요청을 먼저 처리. head movement가 효율적이지는 않음
- SCAN Scheduling
- 한쪽 종단에서 종단으로 계속 움직이면서 들어온 Request들을 처리함
- 하지만 양방향으로 움직이는 것 보다는 한 방향으로 움직이는 게 구현이 편하기 때문에 S-SCAN이라는 게 나옴
- C-SCAN (Circular-SCAN) Scheduling
- 한 방향으로만 헤드를 움직이고, 시작점에서 끝점까지 읽어들인 다음에 되돌아올때에는 아무것도 읽지 않고 다시 첫 시작점으로 돌아온다 (단, 되돌아올 떄 움직임은 무시함)
- Boot Block
- 전원이 꺼졌을 때 컴퓨터를 구동시키기 위한 첫번째 프로그램을 bootstrap이라 했지!
- Boot Block을 flash memory(ROM)에 저장함
RAID: Redundant Arrays of Independent Disks- 읽고 쓰는 성능을 높이고 저장소의 신뢰성을 높이기 위해 사용함!
- 데이터 읽기와 쓰기의 bandwitdh을 늘려야 하는데 병렬로 처리가 가능함
- 저장과 쓰기가 올바르게 되었는지 reliability를 정해줘야함! redundant information을 추가해두면 데이터 깨짐을 방지할 수 있고 꺠졌을 때도 복구할 수 있음
- 하드디스크가 맛가도 안전한 방법을 고민
- 잠깐 영어단어!
- Reliability 신뢰성
- Redundancy 중복성?? 정리해고당한, 불필요한
Redundancy: Improvement of Reliability (데이터의 Reliability를 Redundancy 로 올리는 방법?)- 왜 필요한가?
- N개의 디스크가 있을 때에는 오류가 발생할 가능성이 훨씬 높다
- mean time between failures(MTBF) = 만약 10만 시간에 1번 씩 오류가 발생하는데, 디스크가 100개라면 천 시간마다 한 번씩 발생하는 꼴임. 데이터센터 같은 경우 디스크가 엄청 많은데 매 시간마다 디스크 하나씩 버려야한다면 ㅎㄷㄷ
- 중요한 데이터는 그냥 저장할 수 없다! 실패되도 복원할 수 있어야한다. 신뢰성을 높이기 위해
미러링을 함 (모든 디스크에 중복된 데이터를 저장함)
- 왜 필요한가?
- Paralleism(병렬) : Imporvement in Performance 병렬처리를 하여 성능을 높여보자! (bandwidth을 크게 함)
- striping : 여러 개의 드라이브가 있을 때 전송률을 올리는 데 사용할 수가 있는데 이것을 스트라이핑이라고 함
- bit-level striping : 비트 레벨로 스트라이핑을 한다고 하여 이렇게 함
- block-level striping
- RAID Levels
- mirroring : 높은 신뢰성을 가지나 너무 비쌈 (모든 디스크에 데이터를 동일하게 복제)
- striping : 효과적이지만 신뢰성과 관련은 없음 (두 개 이상의 디스크에 데이터를 랜덤하게 쓰는 방법)
- parity bit : 데이터가 깨졌는지 확인하기 위한 체크용 비트(ex: 전송자는 짝수라했는데 받을떄 홀수로 되어있으면 데이터 신뢰성 잃음!)
- 1 : 1의 개수가 짝수면 even
- 0 : 1의 개수가 홀수명 odd
- 이걸 확장하면 checksum, 더 확장하면 CRC가 됨
- 에러를 감지하고, 에러가 감지되었으면 복구까지 할 수 있는 지 레벨로 분류해보자! 성능과 비용을 트레이드오프 할거임!
- RAID 0 : 아무 것도 저장 안함
- RAID 1 : mirroring
- RAID 4 : block-interleaved parity
- RAID 5 : block-interleaved distributed parity
- RAID 6 : P + Q redundancy (Parity bit와 Queue를 둬서 더 강화시킴)
- Multidimensional RAID 6 : 다차원 RAID
- RAID 0 + 1, RAID 1 + 0 을 조합하여 사용하는 케이스


12. I/O Systems
- 대부분 컴퓨팅에서 I/O는 주된 작업임
- I/O 명령어와 I/O 장치들을 제어하는 것은 OS의 할 일! (교수님 잡담 : 실제 업무에서는 OS 커널을 건드리는 일은 없고, I/O Drivers를 만드는 게 더 중요한데, OS에 대한 이해도는 중요함)
- PC bus (CPU가 bus를 통해 각 영역의 컨트롤러에게 명령을 내림!)

- Memory-Mapped I/O
- I/O 장치에 내리는 명령을 어떻게 전달할 것인가?
- data-in register
- data-out register
- status register
- control register
- Memory-mapped I/O : I/O Address에 어떤 interrupt controller가 매핑되어 있는 지 메모리에 매핑시켜둠
- 그래서 디바이스에 직접 명령어를 전달하지 않고, 메모리에 I/O 명령을 주어서 control register의 역할을 할 수 있게 됨
- I/O 장치에 내리는 명령을 어떻게 전달할 것인가?
- 세 가지 유형의 I/O
polling: or busy-waiting- 상태 레지스터의 상태를 계속 읽으면서 원하는 값이 올때까지 기다림
interrupt- interrupt driven I/O : wait 과 signal (이미지 첨부)
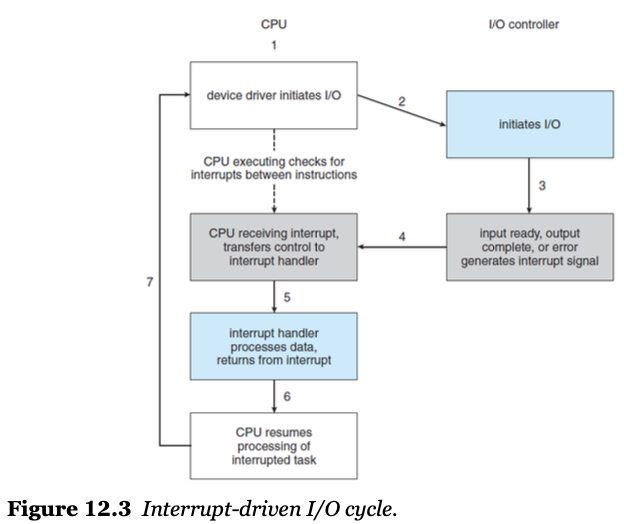
- interrupt-request line이라는 하드웨어로 요소로부터 interrupt가 오면 CPU는 해당 interrupt를 감지하여, CPU는 interrupt를 처리해주는 interrupt service routin(ISR)에게 제어권을 넘겨줌
- interrupt 들을 interrupt vector table에 모아놓고 ISR로 처리
DMA: Direct Memory Access- 아주 대용량 전송의 경우 다이렉트로 메모리에 접근함
- 순서 이미지

- Blocking I/O vs Non-blocking I/O
- Blocking I/O : a thread is suspended
- running 상태에서 waiting queue로 이동
- Non-blocking I/O : does not halt the execution of the thread
- 바로 리턴을 해버리고 waiting queue에 이동하지 않음
- non-blocing VS asynchronous
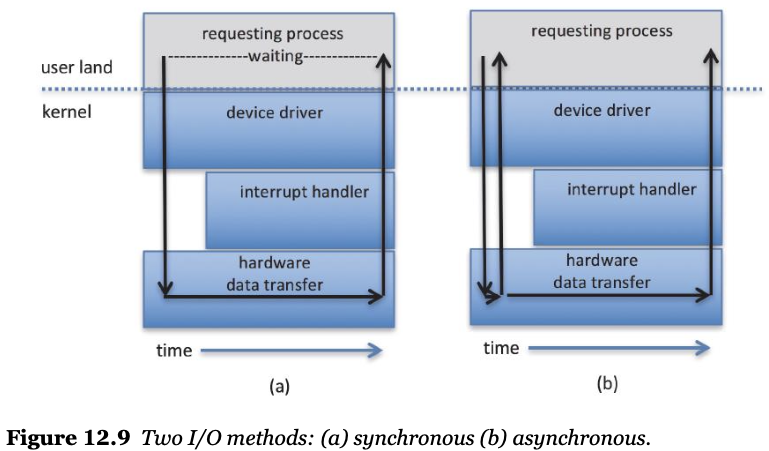
- Blocking I/O : a thread is suspended
13. File System Interface
- File System
- 논리적으로 스토리지에다 데이터와 프로그램을 쓰는 것을 이야기함
- 하드디스크에 물리적으로 데이터 읽고 쓰고 남기는 것은 OS의 할 일, 우리가 관심있는 것은 어플리케이션을 작성할 때 하드 접근해서 읽고 쓰고 안함. Interface를 통해 작성함 (물론 DBMS는 직접 하드 접근)
- 두 가지 파트
- file
- directory
- 접근 방법
- sequential (순차적)
- direct (랜덤 액세스)
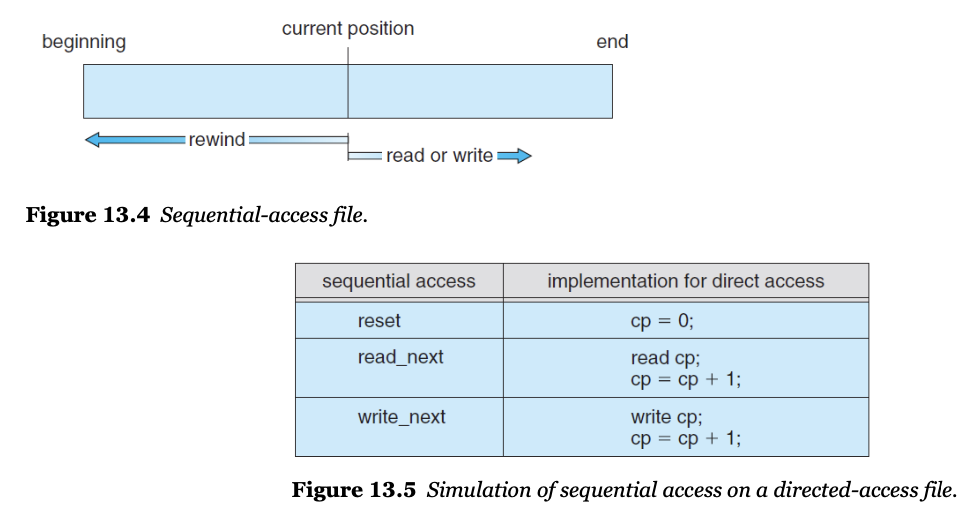
- 디렉토리 구조
- 처음에는 파일 하나에 디렉토리 하나로 single level로 관리함
- 그 이후 two-level
- Tree structured
- Acyclic-graph
- General graph
14. File-System Implementation
- 파일 시스템의 레이어

Allocation Method- 이 파일 시스템에 파일을 어떻게 할당할 것인가? 하드디스크의 섹터를 파일에 어떻게 할당해줄거냐?
- 세 가지 범용적인 사용 방법
- Contiguous Allocation (메모리때 배웠던거랑 유사!)
- 문제점
- external fragmentaion
- need for compaction

- 문제점
- Linked Allocation
- 위 Contiguous 문제들을 해결
- 파일을 block 단위로 쪼개서 링크드 리스트로 연결함!
- 문제점
- 중간부터 데이터를 보고 싶을 경우에도 처음부터 뒤져봐야함 (ex: 동영상)
- 그리고 중간 노드가 깨져서 잃게되면 복구 불가능함 (시작점만 끝점만 알고 있어서 그럼)

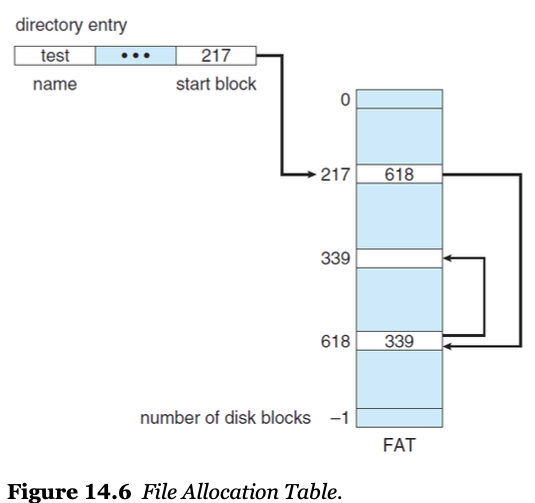
- FAT : File Allocation Table
- 위 Linked Allocation 방법을 좀 더 효율적으로 사용하기 위한 개념
- Linked List에 인덱스 테이블을 추가함
- Indexed Allocation
- Linked Allocation을 FAT랑 효율적이긴 한데 여전히 꼬롬한 문제가 있음(without the FAT) → 여전히 block 자체가 scattered 되어있음 (뭔소린지 모름)
- 하드디스크도 베드 섹터가 있어서 데이터가 깨질 수 있음. 이런 것을 방지하기 위해 링크드 리스트 순서를 인덱스 블록에 다 담아둠
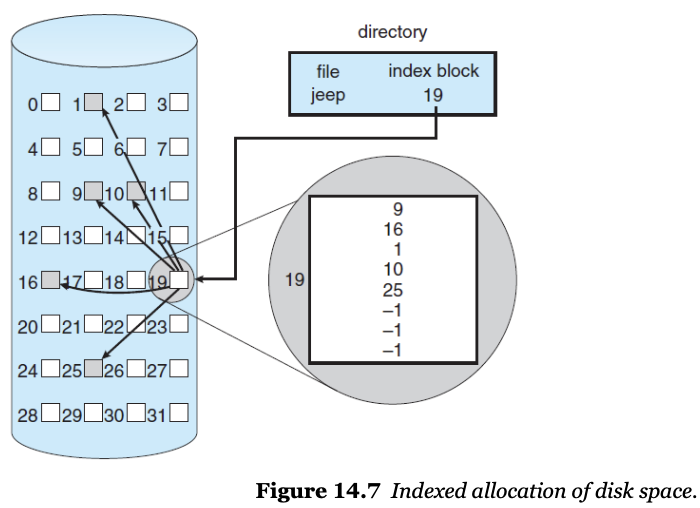
- 파일을 지워도 복원할 수 있는 이유 : Index Block만 찾으면 됌!
- Free-Space Management
- 안쓰는 메모리 공간에 대해서도 알고 있어야함! 링크드 리스트 기반인 경우는 다 필요쓰!

- Contiguous Allocation (메모리때 배웠던거랑 유사!)
퀴즈
반응형
'엔지니어링 > 개발배움터' 카테고리의 다른 글
| [운영체제 공룡책] 16-17. Security & Protection (0) | 2022.09.14 |
|---|---|
| [운영체제 공룡책] 10. Virtual Memory (0) | 2022.09.05 |
| [운영체제 공룡책] 9. Main Memory (0) | 2022.08.29 |
| [운영체제 공룡책] 8. Deadlock (0) | 2022.08.24 |
| [운영체제 공룡책] 7. Synchronization Examples (0) | 2022.08.15 |